Foundation models have proven to be a powerful technology capable of human-like reasoning. But, that reasoning is generic and frozen in time — limited to only the facts on which the models were trained. Worse, models often fail to recognize their own limits, confidently hallucinating inaccurate responses. This is incredibly constraining for developers trying to build personalized generative applications.
The rapidly emerging Generative AI Stack enables new techniques for developers to augment models with data, allowing developers to create rich application experiences by personalizing outputs for each user and workflow, reducing hallucinations, and making models more efficient.
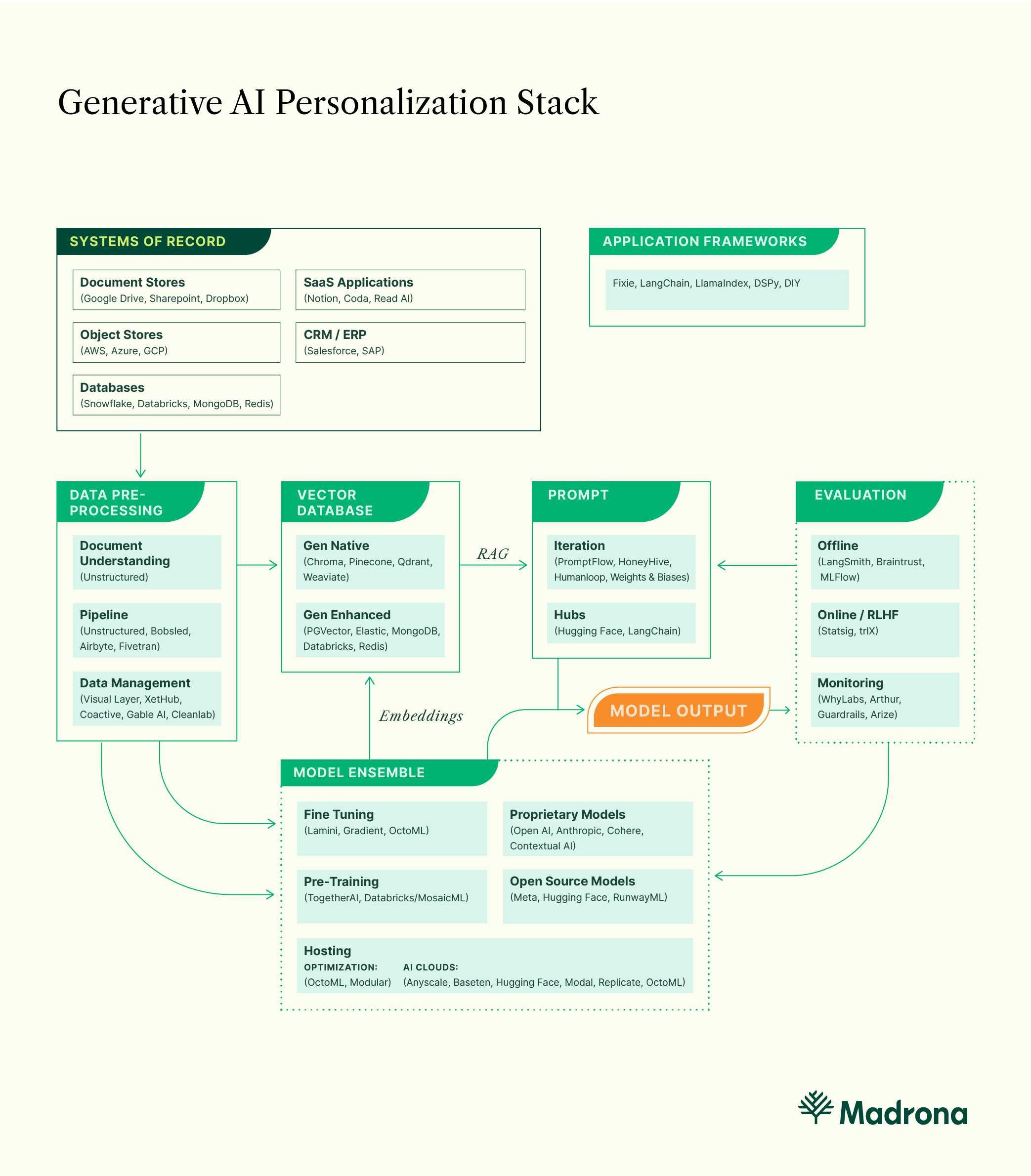
A playbook is materializing for developers building end-to-end generative applications.
- In-Context Learning / Prompt Engineering — Developers iterate on prompts and examples explaining in natural language to the LLM what outputs should look like.
- Retrieval Augmented Generation (RAG) — Developers programmatically feed in natural language data to the model using Application Frameworks.
- Fine-tuning — Developers fine-tune models with application-specific data that the models were not trained on previously.
- Training — In certain scenarios, developers are building entire pre-trained foundation models on their own data.
Ultimately, developers combining these techniques will create differentiated applications and enduring businesses.
Prompt Engineering / In-Context Learning
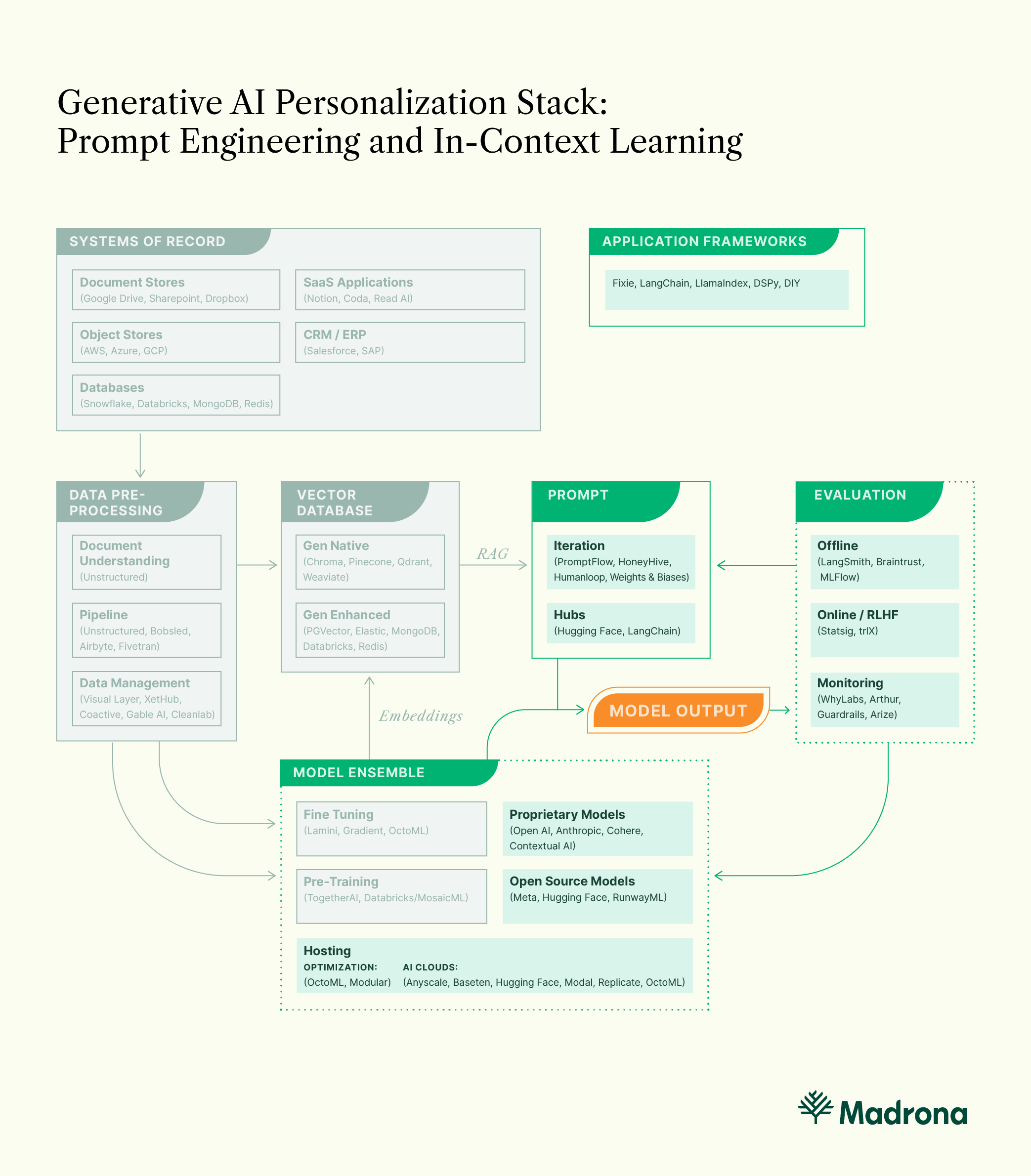
Prompt engineering is the first place to start when influencing model behavior. Prompt construction is more of an art than a science. Each model is nuanced, and getting a feel for how each will behave is time-consuming. Developers can use an emerging set of open-source tools to iterate on prompts quickly, link them together in chains, and even use LLMs to generate prompts. GPT-Prompt-Engineer, Microsoft PromptFlow, and a number of other open-source projects have impressed us. Hubs have emerged for AI engineers to share prompts, including LangChain Hub and HuggingFace Hub. It’s been exciting to witness the stylistic differences in how models can be prompted and how prompts evolve as models become more capable. Developers should consider tools like LangSmith and Braintrust when iterating on prompts and debugging LLM applications.
Evaluation data can also be used to improve models. Techniques like Reinforcing Learning based on Human Feedback (RLHF) involve creating a ranking model that rewards models based on outputs that produce greater user engagement and penalizes outputs that perform poorly. This tuning has proven extremely valuable for model builders that can achieve sufficient distribution. Open AI’s InstructGPT outperforms GPT 3.5 because of RLHF tuning through user upvotes and downvotes within ChatGPT. trlX and other initiatives attempt to provide that same infrastructure for open-source models. Owning the user experience and gaining adoption is critical for experimenting and improving the generative application’s underlying models. Companies like Statsig are enabling rapid experimentation and iteration for the largest LLM applications.
Retrieval Augmented Generation (RAG): Decoupling Reasoning and Knowledge
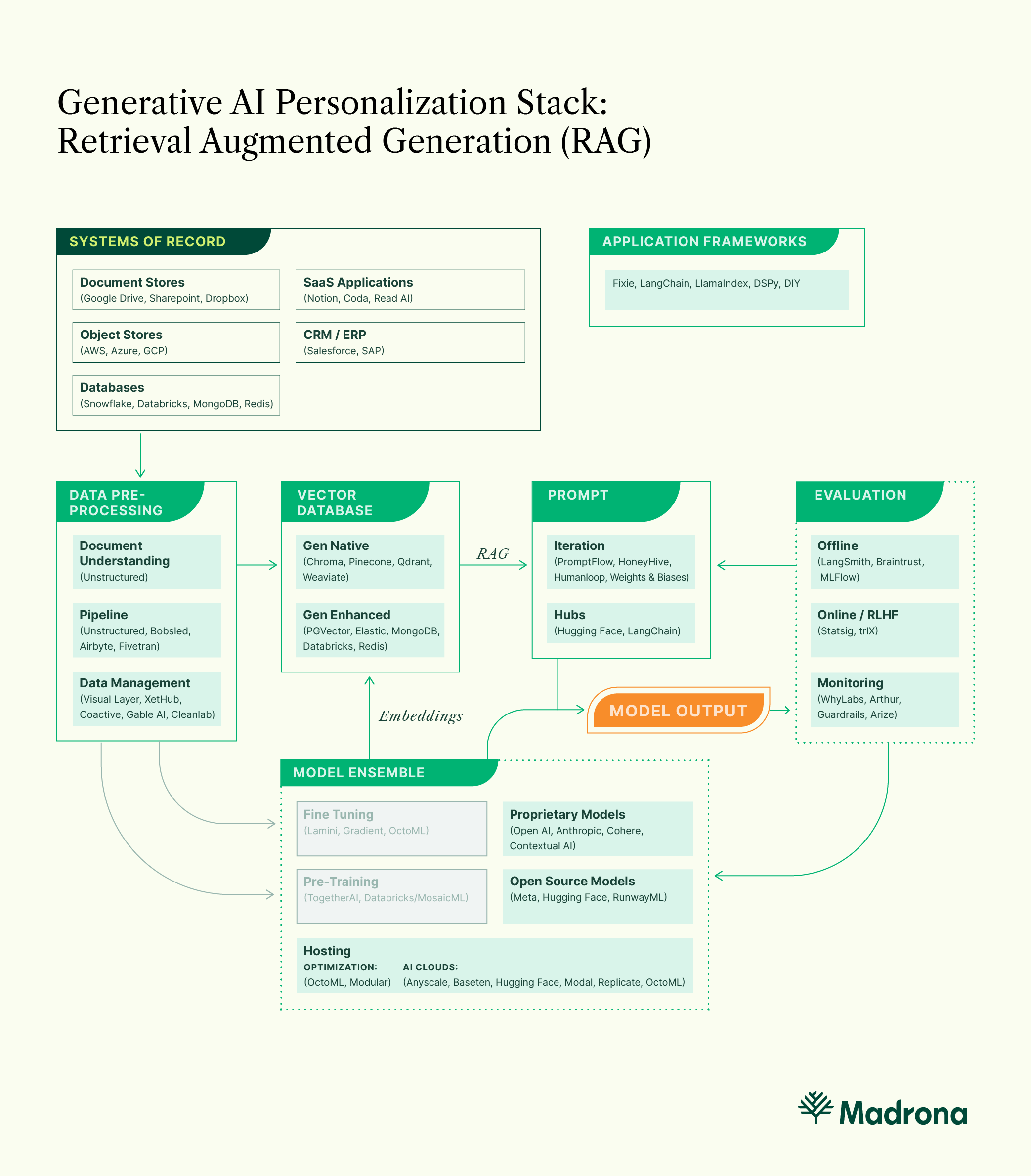
Even with the best prompts, models can hallucinate, mainly because they are limited by the facts on which they were trained. Retrieval Augmented Generation (RAG) allows developers to improve prompts by programmatically giving the model new data on which to act. Over the past six months, we have seen a RAG playbook maturing.
First, developers identify where relevant natural language data is stored within a system of record. In a majority of cases, natural language data is stored within documents. Next, data needs to be pre-processed using a service like Unstructured, so a large language model can readily use it. This includes extracting data from a system of record, transforming the data into a usable format, and loading the data into the model’s context window or a database for retrieval — either a vector database like Pinecone, Weaviate, Qdrant, or Chroma — or existing data stores adding vector capabilities such as MongoDB, Databricks, Postgres, and Elastic are launching vector capabilities. Application frameworks like LangChain and Llama Index have gained popularity helping developers orchestrate this pipeline.
RAG strategies are being used to create personalized and differentiated LLM outputs ranging from enterprise-specific content generation tools, like Typeface, to consumer-oriented LLM-powered assistants like Gather.
Fine-Tuning a Foundation Model

RAG is effective at augmenting generic models with data sources. However, the best personalization may also require fine-tuning or modifying the model’s weights using data. Similar to RAG use cases, developers need to build a data set to fine-tune on by identifying data within systems of record and pre-processing that data using a service like Unstructured.
To fine-tune a model, developers start by selecting a base model. While Open AI models can be fine-tuned, open-source models, like Llama2, give developers the most flexibility to tune the model’s weights. Companies like Gradient and Lamini have launched fine-tuning services. Model hosting services like OctoML, Anyscale, Replicate, and HuggingFace, and services cloud providers launched, like AWS Bedrock, Azure Open AI Service, and Google Vertex AI, provide developers the tools to fine-tune open-source models. Some of these companies, like OctoML, are adding significant value by running a managed service for deploying an ensemble of models that can be optimized to run across different hardware configurations.
The most sophisticated applications increasingly rely on model ensembles that combine frontier models like GPT-4 with a collection of specialized, fine-tuned open-source models to optimize performance with latency and cost.
Fine-tuning models can be risky. Because fine-tuned models are derived from base models, a step function change in the performance of a base model can quickly render a fine-tuned model on the previous iteration of the base model less effective. Fortunately, new techniques like Low-rank adaptation (LoRa) allow developers to update fine-tuned models alongside new versions of base models. Second, fine-tuned models are trained on a fixed data set, meaning, like base models, they can be frozen in time and limited by the facts on which they were trained. For that reason, RAG is highly complementary to fine-tuning.
Build Your Own Foundation Model
In certain scenarios, proprietary models from vendors like Open AI and off-the-shelf open-source models are too generic. In these cases, developers are building vertical-specific foundation models in industries like finance (BloombergGPT) and healthcare (MedPaLM, HippocraticAI).
Creating a pre-trained model is expensive and requires significant resources to curate, clean, and label the correct data set — not to mention the cost for GPUs to train a large enough model. Builders are using Unstructured, Visual Layer, and XetHub to help pre-process and manage such large data sets. MosaicML and Together provide compute platforms to help developers train new models from scratch.
Once built, these models may perform significantly better for the use cases within their domain — especially when paired with frontier models in ensembles. However, it is unclear whether a novel pre-trained model will outperform a fine-tuned model enough to justify the cost.
Closing Thoughts
Incorporating data into applications is paramount for building differentiated and defensible end-to-end applications that best serve customer needs. Developers looking to build intelligent applications that transform the commercial and consumer worlds should consider a combination of In-Context Learning, Retrieval Augmented Generation, Fine-Tuning, and Pre-Training techniques.
At Madrona, we believe that Data will play an increasing role in supercharging generative applications. We’ve invested in companies like Typeface that enable personalized content generation at work and in enablers like Unstructured, building the infrastructure to make personalized generative applications possible.
For founders innovating at the application and infrastructure layers of the stack and builders implementing this stack in production, please reach out at [email protected].